Diego le había aclarado dudas sobre Data Science a otros lectores en los comentarios del blog. Él sabe. Y comparte.
Lo que sigue, valiosa data de alguien cargado de experiencia en esta significativa rama del mundo tech. Aprendí muchas cosas interesantes.
Primero que nada, me presento: Mi nombre es Diego Barboza y trabajo como Data Architect en DataIQ, una consultora especializada en Business Intelligence con sede en Argentina.
Me especializo en el manejo de la plataforma Qlik (QlikSense, QlikView, Geoanalytics) tanto en el Desarrollo, como Administracion y Arquitectura. y mi posición es un híbrido entre un desarrollador y un analista de datos, pero con algo de DBA y mucho foco en visualizaciones e interfaz de usuario.
¿Podrías comentarnos sobre las distintas ramas de la ciencia de datos?
La respuesta corta es que por un lado existe Business Intelligence tradicional que se encarga de analizar la información y producir reportes en forma periódica para que sean consumidos por gerentes en la toma de decisiones mirando el pasado y por el otro existe Data Science que va cambiando dinámicamente y hace exploraciones sobre esos datos, analizando relaciones que no son evidentes y tratando de preveer el futuro… pero la verdad es más compleja.
El ambiente de Data Science es muy complicado, principalmente porque es algo que aún se está definiendo y no hay un consenso unificado sobre el mismo. Hoy en día el Científico de Datos (Data Scientist) tiene el mismo dilema que el Programador tuvo cuando surgió como posición laboral allá por los cincuenta/sesenta ¿Para qué existe? ¿Cuáles son sus tareas? ¿Cuánto debe ganar? ¿Dónde se estudia?
Si me preguntás a mi, la mejor forma de entender qué es la Ciencia de Datos es el siguiente gráfico, porque para entender a dónde vamos, tenemos que saber de dónde venimos:

Los primeros reportes son los excels que va generando el negocio en forma habitual: Asientos contables, Estados de Resultados o PNL (Profit and Loss), Reportes de ventas. Los departamentos de finanzas y contables de las empresas fueron los primeros en empezar a definir una forma de tomar decisiones a partir de los datos, acostumbrados a trabajar con números… sin embargo, a medida que vamos subiendo la escalera, más y más datos se van sumando, se cruza información cada vez más heterogénea y los análisis se van haciendo más y más complejos, hasta que se llega a un punto donde ya no sólo se analiza cuánto se gastó y cuánto se cobró para entender cuánto se ganó, sino que también se empieza a mirar dónde se vendió, quién compró y se empieza a pensar quién podría comprar y qué se podría vender, o cómo se podría vender y qué hay que cambiar en la forma en la que se hacen las cosas para tener un mayor éxito.
Mirándolo de esta manera, puede parecer que el Data Science surge a partir del Business Intelligence, la verdad es que el BI es una forma “simplificada” del DS (Data Science) y que puede implementarse en la mayoría de las empresas de una forma relativamente fácil. Obviamente que una empresa como MELI de Argentina va a invertir grandes recursos en estar a la vanguardia en todos sus frentes, pero una Pyme que apenas le puede pagar a un estudiante para que haga soporte técnico, no va a tener el mismo nivel de inversión en este aspecto, y así nos encontramos con la siguiente graduación:
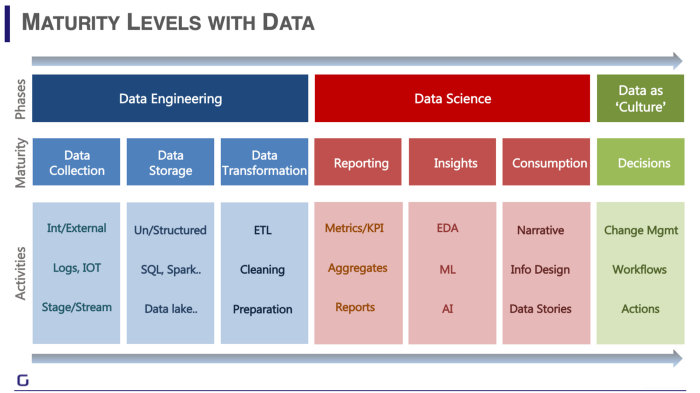
Donde la mayoría de las PyMes se quedan en el primer nivel de la Ingeniería y Ciencia de Datos (Data Collection & Reporting) y las empresas mientras más grandes son, y más alcance tengan, más avanzan en esta escala.
¿Cómo llegaste a trabajar en esto y cuáles áreas son las que te despiertan más interés?
Cuando yo tenía 14 años descubrí una recopilación de cuentos de Ciencia Ficción de Isaac Asimov: Me encantó su estilo y eventualmente compré “Fundación“, que es el primero de una secuela de tres libros donde habla sobre la Psicohistoria, una ciencia que combina la estadística, la matemática y el estudio del comportamiento del total de la población humana para entender su situación actual, preveer su futuro y así tomar las mejores decisiones posibles para la humanidad. Esa novela fue escrita en el 50 y cuando yo la leí, a fines de los 90’s, me parecía algo de ciencia ficción. A mis 28 años (en el 2011) entro a trabajar en un laboratorio como Operador IT y me asignan al departamento de Business Intelligence, mis tareas eran ejecutar procesos de carga, mirar servidores y comparar números, todo explicado en SOP… pero cuando fuí entendiendo lo que querían decir esos números, para qué eran los análisis y cómo se usaba esa información me volví loco, ¡Me sentía un personaje de las novelas de mi autor favorito mirando números y analizando tendencias! Poco a poco fuí metiendome en ese mundo, gracias a que Luciano Kiernan (mi jefe) me dió la posibilidad de comenzar a capacitarme y como yo estaba empezando a estudiar ingeniería le fui agarrando la mano. En un momento quedó vacante una posición para Desarrollador Qlik y cómo podían seguir pagando como operador, pero haciendo tareas de Desarrollador Jr, hice el paso sin problemas. Ahí empecé a trabajar con Pablo Casullo, quien fue mi mentor y me fué iniciando en el mundo de los datos.
Hoy en día me encantan los desafíos, lo que más me gusta es llegar a un cliente y preguntar cuál es el problema que tienen y me interiorizo en el negocio, trato de entender su propósito y los inconvenientes que tienen, a partir de ahí diseño una solución que sirva. En algunos casos, puede ser diseñar una métrica que les permita ver el impacto de varios factores a la vez, otras veces es la automatización de un reporte que hasta ese momento es manual, los casos son más divertidos son los análisis de fraude, pero también es interesante cuando hay un problema y no saben de dónde viene, o siquiera cómo encararlo.
¿Qué herramientas usás habitualmente?
Trabajo mucho con QlikView y QlikSense, ya que mi faceta de desarrollador viene de ese lado, sin embargo Excel es la primer herramienta del BI y es el formato que más fácilmente se puede manejar en cualquier negocio y que en cualquier lugar entienden: Con decirte que en una oportunidad tuve que diseñar un dashboard exactamente con el mismo look & feel del excel con el que trabajaban para que el cliente aceptara la aplicación que estaba desarrollando.
Otra herramienta que uso muchísimo es SQL, ya que es raro encontrar una empresa que no tenga un DW diseñado en Oracle, o procesos que dejen info en MySQL. SAP cada vez se está haciendo más moneda corriente (sobre todo HANA & BW) pero para interpretar esos datos suelo tener ayuda del lado del negocio. Por lo general, uso Qlik para consolidar datos de todas las fuentes, por más heterogéneas que sean, y luego a partir de ahí voy depurando la data para producir las visualizaciones que me permitan mostrar las métricas que me pidieron o bien que yo he diseñado con mi análisis.
He hecho cursos para desarrollar en R, y manejo algo de Python , pero hasta ahora no he tenido la suerte de participar en forma activa en un proyecto de analítica avanzada. Estoy empezando un proyecto por mi cuenta para jugar un poco con Python, pero como todos los proyectos que uno hace en el tiempo libre, el tiempo de avance es bastante lento, je…
En algunos casos se hacen cambios en el CSS, y cada vez es más común interactuar con APIs a partir de las cuales se levanta data en JSON, por eso es importante consultar la documentación de cómo fueron desarrolladas las APIs para poder interpretar esos datos.
¿Podrías recurrir a tu experiencia y contarnos sobre cómo se trabaja según el tamaño de la empresa y el rango de proyectos que uno puede encontrar?
Por lo general, a partir de la inversión que una empresa haga en el manejo de los datos te podés dar cuenta de que tan grande es una empresa y qué tanta proyección a futuro tiene. Por lo general en las PyMEs o en emprendimientos pequeños no suele haber inversión en lo que es Business Intelligence y Data Analytics, a menos que sea un emprendimiento fuertemente relacionado con sistemas o tecnología. Por lo general, son las empresas más grandes y las que tienen mayor visión a futuro las que suelen invertir en el procesamiento de datos para toma de decisiones… e incluso en algunos lugares lo hacen porque “Hay que hacerlo” y la gerencia, aunque no esté muy convencida, lo hace de cualquier manera: Lo más tradicional es encontrar automatización de reportes, PNLs, análisis de producción y finanzas (proyectos de 2 o 4 meses). En otras empresas, sin embargo, cada vez están surgiendo más “socios” del lado del negocio que realmente quieren entender la situación y que apoyan las inversiones en este aspecto y dan feedback sobre los resultados logrados, es una tendencia que va ganando fuerza de a poco, cuando esto ocurre (y hay un equipo con la suficiente capacidad técnica) se pueden comenzar a desarrollar proyectos de analítica avanzada, donde se trata de predecir el comportamiento de los clientes, de la competencia o el mercado en general a partir de modelos estadísticos y apoyándose en el conocimiento del negocio, sin embargo desarrollos suelen llevar tiempo y no producen resultados inmediatos (1 o 3 años, si hay resultados).
Durante el año pasado (2019) tuve la suerte de trabajar en para la división de Nación Servicios (Banco Nación) y allí realizamos trabajos muy interesantes relacionados con la parte de fraudes, además de analizar el uso de la tarjeta SUBE: las líneas más utilizadas, eficiencia de los subsidios otorgados, frecuencia real de los colectivos, etc… Ese proyecto fue particularmente gratificante porque pude ver que hay gente como Diego Castro y Martin Khal que se preocupan por usar la tecnología para hacer un mejor uso de los recursos del estado.
Por lo que entiendo, la tenés bastante clara en herramientas de visualización, ¿no?
Bueno, si: es la base de mi trabajo; siendo completamente honestos, por momentos me siento más un usuario avanzado de una plataforma que un “programador real”. Es como si me pagaran por desarrollar en Excel. Obviamente, a veces para armar una visualización determinada tengo que armar todo un ETL copado, con determinadas iteraciones, cruce de datos, pivoteo de tablas y relaciones relevantes, o definirlas en forma dinámica… y hago MUCHO análisis de datos. A veces tengo que pedirle a un fullstack que cree determinado objeto, o a un diseñador que me modifique un CSS para poder graficar algo de una forma particular (principalmente, por cuestiones de tiempo)… pero mi principal tarea es analizar los datos y darle un sentido, crear una narrativa. Hoy en día la herramienta de visualización de datos más popular (y más nueva) es PowerBI , por sus similitudes con Excel y su fácil integración con todo el entorno de Microsoft, pero Tableau está establecida desde hace tiempo y mucha gente ya la maneja. Cognos es algo obsoleto en algunos aspectos, pero muchos gerentes de grandes empresas no lo van a dejar de usar, y va a seguir así hasta que haya un cambio generacional (que ahora está ocurriendo) todas estas herramientas requieren un ETL en el que apoyarse, ya sea Oracle, Teradata, Azure, Hadoop o AWS.
Relacionado con mis tareas, puede parecer tonto que a veces mi principal función sea elegir tal o cual gráfico o marcar una visión determinada para el análisis de una situación, pero hay veces que yo puedo ver determinada situación a traves de los datos que si no se grafica correctamente, el negocio puede terminar ignorando mi análisis.
Dado que ustedes le acercan información sumarizada a quienes toman decisiones ¿Dónde encontrás lo relevante? ¿Cómo y cuándo crean significado?
En una empresa donde trabajé lo tenían bastante bien armado: una persona realizando el rol de Data Scientist coordinando el trabajo de un equipo de 7 personas, y en ese equipo había 4 desarrolladores de distintas plataformas, un full stack y un par de personas que solo manejaban excel, pero tenían fuerte conocimiento del negocio: el DS manejaba todo desde la estadística y le iba pidiendo cosas a los desarrolladores, y analizaba los datos junto con la gente del negocio para entender los problemas.
Literalmente miraba todo. Para mi el tema se maneja mucho mejor así, no podés esperar que un DS maneje todo, encima desarrolle y esté al tanto de cada cosa técnica. Hay distintas formas de encarar un problema y no podes esperar juntar todo el conocimiento en una sola persona, por eso es importante la especialización.
¿Qué te parece lo más aburrido, cómo se compensa y qué intentás esquivar o evitar?
Una tarea tediosa es la documentación, pero es un mal necesario: Si no queda claro que es lo que hiciste, o por qué definiste tal tarea, entonces se corre el riesgo que a futuro alguien rompa algo tratando de arreglar una cosa y ahí se complique todo. Personalmente, trato de reducir la necesidad de documentación detallada trabajando en forma modular, separando los procesos de transformación de datos en unidades lógicas con tareas definidas fácilmente entendibles por el negocio por dos razones:
1) El concepto es más fácil de entender (ej: si se quiere cambiar la dirección de los clientes, solo hay que mirar en el STG de clientes y ahí solo es necesario mirar el módulo de dirección)
2) El impacto es menor (si se rompe el módulo de dirección de clientes, solo hay que hacer un restore de ese módulo y listo)
Una tarea muy aburrida es el ida y vuelta que por la UX: hay veces que los usuarios no quieren determinado color, o quieren cambiar la paleta, o la fuente y distribución de los objetos no les convence y se pueden pasar días enteros dando vueltas sobre lo mismo. Trato de evitar demorar la entrega del proyecto final pidiéndole a los clientes que definan el look and feel de entrada (ya sea armandolo en PowerPoint, Excel, paint o lo que sea) pero no siempre lo tienen claro y uno tiene que adivinar sobre la marcha. Lo peor es cuando dicen que no es importante y le dan completa libertad a uno y, en el momento de entregar, quieren redefinir toda la interfaz gráfica. Hasta ahora, la mejor práctica que encontré para reducir el impacto de esto es tratar de definir un indicador principal, preparar un mockup mostrando ese indicador y dárselo al usuario en las primeras semanas, diciéndole “así es como se va a ver la aplicación” y de esa manera ya me voy adelantando a sus críticas, y así puedo llevar el desarrollo hacía algo que le resulte agradable y fácil de leer.
¿Qué cosas crees que se destacan en un CV de Data Scientist y cuáles creés que suelen estar demás?
Experiencia y Estadística. Lo más importante de un buen Data Scientist es tener fuertes conocimientos en estadística y modelos matemáticos para hacer análisis y que tenga experiencia haciendo ese trabajo.Las capacidades técnicas son algo secundario: el hecho de que maneje muchas plataformas es algo anecdótico casi. Personalmente, prefiero a alguien que solo haya trabajado con Python toda su vida para hacer modelos predictivos, pero que tenga experiencia, porque si tiene que empezar a trabajar en R, o si tiene que usar otra plataforma, se puede apoyar en el conocimiento técnico que alguien más tenga para plasmar los procesos lógicos que él va a diseñar. Lo mismo aplica si es alguien que trabajó toda su vida haciendo análisis con DW montados en Oracle pero tiene que empezar a trabajar con AWS o Azure: si alguien puede explicarle las diferencias técnicas entre uno y otro, ayudándolo a hacer el salto técnico, la parte conceptual ya la tiene clara y eso es lo más difícil de aprender.
Algunas personas son buenas para realizar tareas al pie de la letra, destacándose en roles operativos; otros son creativos y tienen la capacidad de reducir problemas complejos a conceptos simples, estos suelen ser excelentes programadores/desarrolladores; Y a algunos nos gusta analizar datos, realizar comparaciones y hacer preguntas que a nadie se le ocurrieron, y ese es el potencial de un buen Data Scientist.
¿Qué tipo de estrategias podría seguir quien busque comenzar o cambiarse a este rubro?
Hoy por hoy, se pueden hacer cursos, pero yo creo que lo mejor es ir comenzando de a poco. Lo ideal es ir recorriendo este camino y a partir de ahí, si le gusta lo que encuentra, seguir adelante… sino, cambiar de rumbo:
1- Curso de Data Visualization (cualquier curso gratuito puede ser útil, la idea es ir aprendiendo el glosario y nociones básicas de visualización)
2- Aprender Excel y usarlo para resolver un problema (analizar/planificar tus finanzas, analizar cosas de juegos o del trabajo, etc…)
3- SQL y Nociones básicas de DW: Kimball vs Inmon
4- Elegir una herramientas de visualización: PowerBI / Tableau (ambos son gratis ) y retomar el proyecto de 2 y ampliarlo creando un Data Warehouse y usar una herramienta de visualización
5- Aprender nociones básicas de Estadística y probabilidad
6- Buscar un curso de Python o R para Data Analytics. (Hay cursos gratuitos y no hay que pagar licencias)
Ahora bien, estos primeros 6 pasos le permiten a uno tener una base más o menos clara de lo que es el universo de datos, e incluso uno puede ya ingresar como SSR Desarrollador BI (si ya tiene experiencia previa en IT), lo cual nos brindará la experiencia para hacer luego el salto a Data Scientist. En este punto ya sería conveniente buscar un curso de Data Scientist más serio, yo recomiendo ITBA o Digital House ¿y por qué no empezar directamente con estos cursos? Porque estos cursos abarcan demasiados aspectos y son muy intensos, por lo que es difícil seguir el ritmo; en cambio, si uno se prepara anteriormente aprovechará mejor estos cursos al máximo, porque ya contará con el vocabulario básico y una experiencia en la que apoyarse.
¿Hay mucho de matemática, álgebra y/o estadística?
La estadística es la base del trabajo de todo buen Data Scientist. Prácticamente, es lo que lo define.
Ya que te gusta lo que hacés (estás en la movida con conferencias) ¿Algún otro tipo de recomendaciones y sugerencias?
– No es necesario ser un Data Scientist para usar sus herramientas: El apoyar las decisiones que tomes con datos es el primer paso para planificar a futuro, no solo profesionalmente, sino también en tus finanzas personales.
– Le recomiendo a todo el mundo aprender a usar Excel, PowerBi, Tableau o cualquier herramienta de visualización y manejo de datos. Te abre puertas y te ayuda a pensar de otra manera.
– Investigar y tener una actitud crítica hacia la información que nos encontramos es algo que siempre aplica.
– Medir la performance de nuestro trabajo: hs estimadas vs hs trabajadas, discriminar horas de investigación, horas de estimación y planificación, horas de desarrollo real y horas de retrabajo nos va a permitir identificar nuestras fortalezas y debilidades. Es importante hacer BI sobre cómo desarrollamos. Lo que no se mide, no se mejora.
Para cerrar, ¿Qué tendencias intuís que se están formando? ¿Hay tecnologías o habilidades en las que convenga mantenerse afilado?
– Todo lo que es AWS y Azure (en resumen, Hadoop) es algo que cada vez se viene popularizando e imponiendo cada vez más, en la mayoría de las empresas, por lo que conviene mucho aprender a cómo interactuar con esas tecnologías. Sin embargo, todo lo que es Big Data es como el sexo adolescente, en el sentido que: Nadie está muy seguro que es y todos dicen que lo hacen, pero nadie sabe si lo está haciendo bien.
– Hay sobreabundancia de Cursos en Python y R para data analytics, por lo que intuyo que en el mediano plazo pueden convertirse en un requisito común en el mediano plazo; sin embargo, Python es bastante fácil si uno viene de Java, por lo que creo que es mejor tratar de aprender nociones de estadística y manejo de datos, más que nada para familiarizarse con el glosario y poder dialogar de igual a igual con cualquier Data Scientist o Data Analyst que nos toque interactuar: si uno aporta la especialización técnica en la rama que uno maneja, lo importante es poder entender el vocabulario del otro lado para poder trabajar mejor.
– En nuestro sector (IT) la comunicación es algo que muchas veces subestimamos y no nos damos cuenta que eso termina provocando que haya posiciones cuya única función termina siendo aceitar la comunicación entre sectores (PMs, ScrumMasters, Product Owners, etc…)
Un crack Diego.
Si te interesa evitar que usen inteligencia artificial para mostrarte anuncios de cosas que tal vez quieras (pero no necesitas) entonces te invito a probar Brave: un Chrome mejorado que bloquea publicidades (incluido youtube). Bajalo y disfrutalo de acá.
Gracias por la oportunidad de compartir la info Facundo! Y para cualquiera que tenga una duda, estoy disponible para responder cualquier consulta. Ask me anything!
Muchísimas gracias Diego y Facu !!. Se lo voy compartir a mis compañeros de la facu que estamos en el ultimo año analizando que perfil seguir cada uno , ya que el mundo IT es tan amplio que uno se termina mareando . Me gustaron mucho tus recomendaciones sobre como ir familiarizandote en el tema . Me llamo la atención la importancia de esta area que la UBA para 2021 abre la carrera de ciencia de datos . Nosotros en la facu estamos “jugando” con weka un software educativo para analizar datasets. Una preguntita ,el Business analyst (BI) puede tambien tomar el rol de Data analyst ? Saludos
El rol del Business Analyst (BA) es diferente al Data Scientist(DS), aunque el ambos tienen algunas cosas en común, ya que en ausencia de un Data Scientist, el Analista del Negocio es quien:
– Establece los objetivos
– Define la criticidad de los temas a trabajar
– Analiza los datos e interpreta los resultados
– Tiene conocimiento (funcional y técnico) de los datos.
Sin embargo, hay tareas del DS que escapan a un BA, como por ejemplo:
– Definir modelos matemáticos
– Crear/Modificar modelos de datos (tambien Data Architect)
– Definir las plataformas en las cuales se trabajará (tambien Data Architect)
– Establecer la estrategia de ML / IA
– Definir como se trabajará la cultura de datos
– Realizar nuevas conexiones de datos y definir sus relaciones.
Son roles similares, pero el DS tiene un alcance mucho mayor. Donde hay mayor solapamiento es entre un Business Analyst y un Data Analyst, incluso yo creo que vienen a ser casi lo mismo: roles hibridos con algo de conocimiento técnico en el manejo de datos(how?) y fuertes conocimientos del negocio (what?), solo que uno es mas general (DA) y el otro es mas específico de una industria (BA)
muchisimas gracias Diego , quedo super claro !! !!!